BIOINF-3010-7150
Bash Practical Part 1
- Introduction to Bash
- Regular Expressions
Introduction to Bash
Virtual Machines
The practicals that you will be participating in will make use of cloud compute resources that are provided by The University as a virtual machine (VM).
The VM is essentially a program that is running on a server but which behaves as though it is an individual separate computer.
You will be able to log in to the VM and interact with the programs that it has installed.
The VMs provided each have 2 virtual CPU cores, 16GB of system memory and a lot of shared hard disk space. That said, I encourage you to keep your stored files to a sensible minimum. Delete old data that you have moved from ./data to your directory as it can be moved back if needed.
They are yours to use for the semester, but they are also yours to look after.
The University runs these VMs on AWS RONIN (Amazon Web Services) and pays by the minute for cpu time and for the storage. Because of this, we have implemented auto shutdown of VMs if they remain idle for too long (idle means no jobs running or no user input).
Please go here for instructions on connecting to your VM.
RStudio
You will be using a program called RStudio to interact with your VM. Each VM has RStudio Server running on it and serving a web page that you can interact with via a web browser.
When you have connected to the VM, you should see something that looks like this.
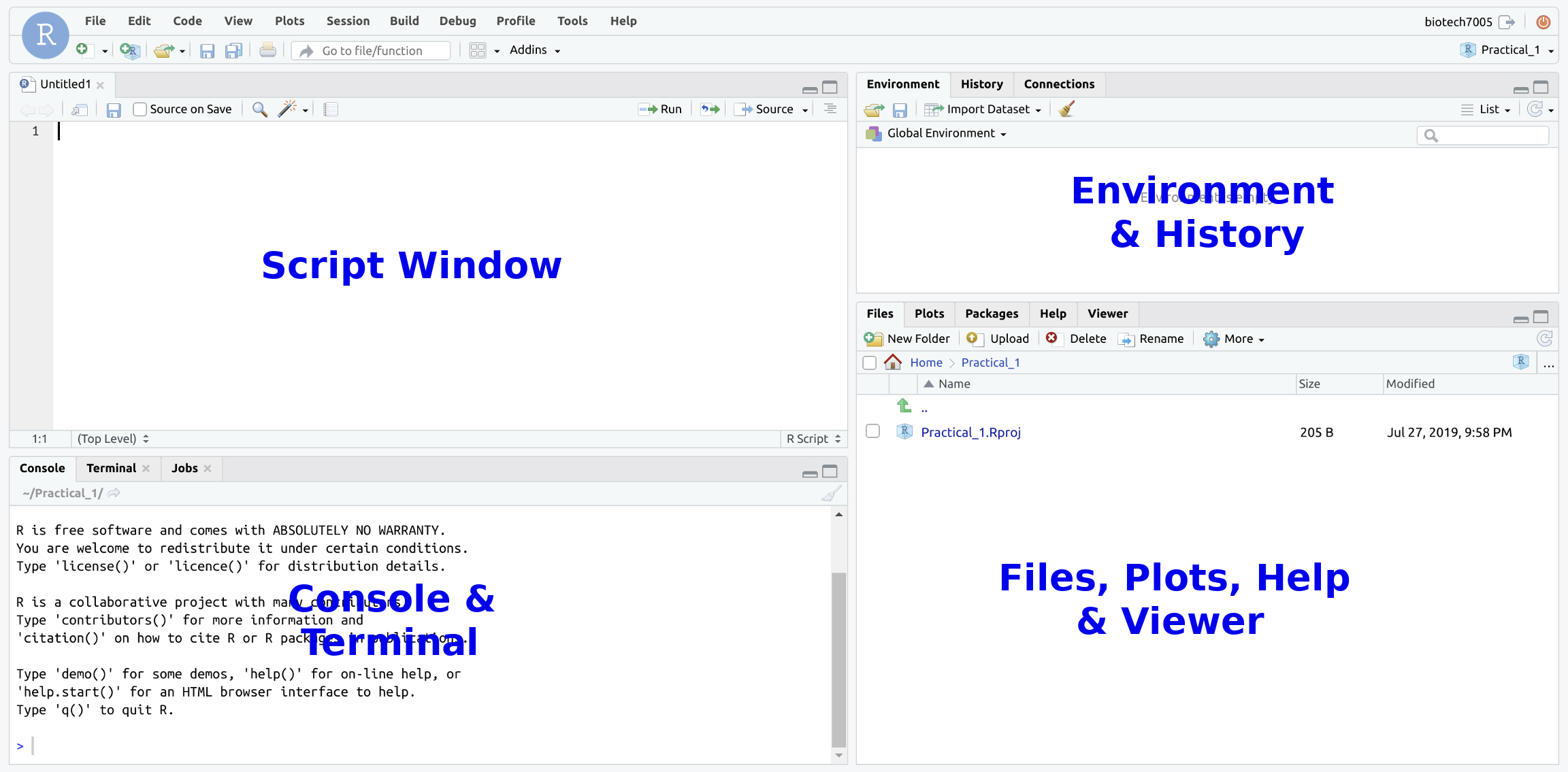
You will only be using the Terminal part (pane) of the RStudio window. You can maximise the Terminal pane with the icon on the top right of that section of the window.
An important step in many analyses is moving data around on a high-performance computer (HPC), and setting jobs running that can take hours, days or even weeks to perform.
For this, we need to learn how to write scripts which perform these actions, and the primary environment for this is bash.
We can utilise bash in two primary ways:
- Interactively through the terminal
- Through a script which manages various stages of an analysis
For most of today we will work interactively, however a complete analysis should be scripted so we have a record of everything we do. This is often referred to as Reproducible Research, and in reality, our scripts are like an electronic lab book and will help you remember exactly what analyses you have performed. When you’re writing up methods for a report, paper or thesis, referring back to your scripts will be very useful.
Running bash on your VM
All computers running MacOS and Linux have a terminal built-in as part of the standard setup, whilst for Windows there are several options, including git bash which also enables use of version control for your scripts.
To keep everything consistent for this practical, we’ll use the terminal which is available inside RStudio.
Note that even though we’re using RStudio, we won’t be interacting with R today as R runs interactively in the Console.
Instead we’ll be using one of the other features provided by RStudio to access bash
To access this, open RStudio and make sure the Console window is visible.
Inside this pane, you will see a Terminal Tab so click on this and you will be at an interactive terminal running bash.
We’ll explore a few important commands below, and the words shell and bash will often be used interchangeably with the terminal window.
If you’ve ever heard of the phrase shell scripts, this refers to a series of commands like we will learn in these sessions, strung together into a plain text file, and which is then able to be run as a single process.
Although we haven’t specifically mentioned this up until now, your virtual machines are running a distribution of Linux, and we can access these machines by logging in remotely, as well as through the RStudio interface.
Setup the directory for today
First we will set up a directory for today’s practical. In general it is very worthwhile to keep all your project-specific code and data organised into a consistent location and structure. This is not essential, but is very useful and is good practice. If you don’t follow this step, you will be making your life much harder and will not be following ‘best practice’ data analysis. For practicals where R will be used, everything will be harder if you do not follow the equivalent strategy there.
To make and enter the directory that you will be working in, run the following commands in the terminal pane (try to figure out what they mean — we will be going over them more later in the prac).
mkdir ~/Project_0
cd ~/Project_0
You will now find yourself in this directory you have created.
If you look at the bottom right pane of your RStudio session you will see Project_0 appeared when you executed mkdir ~/Project_0.
If you need to, you can navigate through the directories and select files with the file navigation pane just as you would with a normal file browser.
Making this directory to work in will help you keep everything organised so you can find your work later. Managing your data and code well is a considerable challenge in bioinformatics.
Initial Goals
Now we have setup our VM, the basic aims of the following sessions are:
- Gain familiarity and confidence within the Linux command-line environment
- Learn how to navigate directories, as well as to copy, move and delete the files within them
- Look up the name of a command needed to perform a specified task
- Get a basic understanding of shell scripting
Finding your way around
Once you’re in the Terminal section of RStudio, you will notice some text describing your computer of the form
a1234567@ip-10-255-0-115:/shared/a1234567/Project_0$
The first section of this describes your username (a1234567) and the machine @ip-10-255-0-115.
The end of the machine identifier is marked with a colon (:).
After the colon, the string (~/Project_0) represents your current directory, whilst the dollar sign ($) indicates the end of this path and the beginning of where you will type commands.
This is the standard interface for the Bourne-again Shell, or bash.
Where are we?
pwd
Type the command pwd in the terminal then press the Enter key and you will see the output which describes the current directory you are in.
pwd
The command pwd is what we use to print the current (i.e. working) directory.
/shared/a1234567/Project_0
Check with your neighbour to see if you get the same thing. If not, see if you can figure out why.
At the beginning of this section we mentioned that ~/Project_0 represented your current directory, but now our machine is telling us that our directory is /shared/a1234567/Project_0.
This raises an important and very useful point.
In bash the ~ symbol is a shortcut for the home directory of the current user.
If Dave was logged in, this would be /shared/Dave whilst if Anna was logged in this would be /shared/Anna.
As we are all logged on as aXXXXXXX, this now stands for /shared/a1234567.
Importantly every user with an account on one of our virtual machines will have their own home directory of the format /shared/a1234567, /shared/a1234568 etc..
Notice that they will all live in the directory /shared which is actually the parent directory that all users on our system will have a home directory in, as we’ve just tried to explain.
This can be confusing for many people, so hopefully we’ll clear this up in the next section or two.
In the above, the /shared directory itself began with a slash, i.e. /.
On a unix-based system (i.e. MacOS and Linux), the / directory is defined to be the root directory of the file system.
Windows users would be more familiar with seeing something similar, the C:\ directory as the root of the main hard drive, although there are fundamental but largely uninteresting differences between these systems.
Note also that whilst Windows uses the backslash (\) to separate parts of a directory path, a Linux-based system uses the forward slash (/), or more commonly just referred to simply as “slash”, marking another but very important difference between the two.
cd
Now we know all about where we are, the next thing we need to do is go somewhere else.
The bash command for this is cd which we use to change directory.
No matter (almost) where we are in a file system, we can move up a directory in the hierarchy by using the command
cd ..
The string .. means one directory above (the parent directory), whilst a single dot represents the current directory.
Directory structure as a tree
This what the directory structure of the root level directory looks like, where the . represents /.
.
├── Anaconda3-2022.10-Linux-x86_64.sh
├── apps
├── bin -> usr/bin
├── boot
├── dev
├── environment -> .singularity.d/env/90-environment.sh
├── etc
├── home
├── init
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libexec
├── libssl1.1_1.1.0g-2ubuntu4_amd64.deb
├── libx32 -> usr/libx32
├── media
├── mnt
├── opt
├── proc
├── rocker_scripts
├── root
├── run
├── sbin -> usr/sbin
├── shared
├── singularity -> .singularity.d/runscript
├── srv
├── sys
├── tmp
├── usr
└── var
This is what the structure of my home directory /shared/a12345657/ looks like, where the. represents /shared/a1234567/
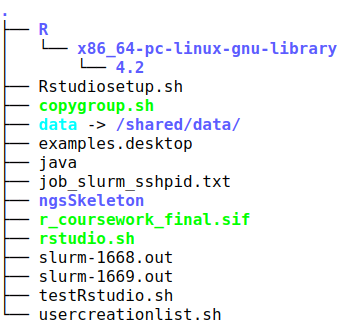
Your home directory may differ slightly from mine.
Question
From which directory will cd .. not move to the parent directory?
Enter the above command and notice that the location immediately to the left of the $ has now changed.
Enter pwd again to check this makes sense to you.
If we now enter
cd ..
a couple more times and we should be in the root directory of the file system and we will see / $ at the end of our prompt.
Try this and print the working directory again (pwd).
The output should be the root directory given as /.
We can change back to our home folder by entering one of either:
cd ~
or
cd
The initial approach taken above to move through the directories used what we refer to as a relative path, where each move was made relative to the current directory. Going up one directory will clearly depend on where we are when we execute the command.
An alternative is to use an absolute path.
An absolute path on Linux/Mac will always begin with the root directory symbol /.
For example, /foo would refer to a directory called foo in the root directory of the file system (NB: This directory doesn’t really exist, it’s an example).
In contrast, a relative path can begin with either the current directory (indicated by ./) or a higher-level directory (indicated by ../ as mentioned above).
A subdirectory foo of the current directory could thus be specified as ./foo, whilst a subdirectory of the next higher directory would be specified by ../foo.
If the path does not have a ./ or ../ prefix, the current directory is used, so foo is the same as ./foo.
Another common absolute path is the one mentioned right at the start of the session, specified with ~, which stands for your home directory /shared/a1234567, which also starts with a /.
We can also move through multiple directories in one command by separating them with the slash /.
For example, we could also get to the root directory from our home directory by typing
cd ../../
Return to your home directory using cd.
In the above steps, this has been exactly the same as clicking through directories in our graphical folder interface that we’re all familiar with.
Now we know how to navigate folders using bash instead of the GUI.
This is an essential skill when logged into a High Performance Computer (HPC) or a Virtual Machine (VM) as the vast majority of these run using Linux without a graphical user interface.
Important
Although we haven’t directly discovered it yet, most file systems used on Unix-based systems such as Ubuntu are case-sensitive, whilst Windows file systems are usually not.
For example, the command PWD is completely different to pwd and doesn’t actually exist on your (or any) default installation of bash.
Note that while MacOS is a unix behind the scenes, it has a semi case-insensitive file system by default.
This will cause you pain if you are not aware of it.
If PWD happened to be the name of a command which has been defined in your shell, you would get completely different results than from the intended pwd command.
Most bash tools are named using all lower-case, but there are a handful of exceptions.
We can also change into a specific directory by giving the path to the cd command using text instead of dots and symbols.
Making sure you’re in your home directory we can change back into the Project_0 directory
cd
cd Project_0
pwd
This is where we started the session.
Tab auto-completion
Bash has the capacity to provide typing suggestions for command names, file paths and other parts of commands via a feature called auto-completion. This will help you avoid a ridiculous number of typos.
If you start typing something bash will complete as far as it can, then will wait for you to complete the path, command or file name. If it can complete all the way, it will.
Let’s see this in action; change into your home folder and make two new directories. These directories are just to demonstrate some aspects of tab auto-completion.
cd
mkdir Practical_1
mkdir Practical_2
Now to change back into your Project_0 folder, type cd P without hitting enter.
Instead hit your Tab key and bash will complete as far as it can.
If you have setup your directories correctly, you should see this complete to cd Pr which is unfinished.
You also have Practical_1 and Practical_2 in your home folder, so bash has gone as far as it can.
Now it’s up to us to enter the next letter a or o before hitting TabEnter. If you enter a as the next letter cd Pra it will complete to cd Practical_ which is as far as it can go.
When faced with multiple choices, we can also hit the Tab key twice and bash will give us all available alternatives.
Let’s see this in action by changing back to our home folder.
cd
Now type cd Pr and hit the Tab key twice and you will be shown all of the alternatives.
You’ll still have to type the o though to get to Project_0.
Another example which will complete all the way for you might be to go up one from your home folder.
cd
cd ..
Now to get back to your home directory (/shared/a1234567) start typing cd a followed by the Tab key.
This should auto-complete for you and will save you making any errors.
This also makes navigating your computer system very fast once you get the hang of it.
Importantly, if tab auto-completion doesn’t appear to be working, you’ve probably made a typo somewhere, or are not where you think you are. It’s a good check for mistakes.
You can now delete empty Practical_1 and Practical_2 directories.
rmdir ~/Practical_1
rmdir ~/Practical_2
Question
Are the paths ~/Practical_1 and ~/Practical_2 relative or absolute paths?
Looking at the Contents of a Directory
There is another built-in command (ls) that we can use to list the contents of a directory.
This is a way to get our familiar folder view in the terminal.
Making sure you are in your home directory (cd ~), enter the ls command as it is and it will print the contents of the current directory.
ls
This is the list of files that we normally see in our graphical folder view that Windows and MacOS show us by default.
We can actually check this output using RStudio too, so head to the Files tab in the Files window.
Click on the Home icon ( ) and look at the folders and files you can see there.
Do they match the output from
) and look at the folders and files you can see there.
Do they match the output from ls?
Ask for help if not.
Alternatively, we can specify which directory we wish to view the contents of, without having to change into that directory.
Notice you can’t do actually this using your classic GUI folder view.
We simply type the ls command, followed by a space, then the directory we wish to view the contents of.
To look at the contents of the root directory of the file system, we simply add that directory after the command ls.
ls /
Here you can see a whole raft of directories which contain the vital information for the computer’s operating system.
Among them should be the /shared directory which is one level above your own home directory, and where the home directories for all users are located on our Linux system. Note that our system is a special case and most Linux systems have user home directories in /home, not /shared.
Have a look inside your Project_0 directory from somewhere else. Tab auto-completion may help you a little.
cd
ls Project_0
Navigate into this folder using you GUI view in RStudio and check that everything matches.
Question
Give two ways we could inspect the contents of the / directory from your own home directory.
Creating a New Directory
Now we know how to move around and view the contents of a directory, we should learn how to create a new directory using bash instead of the GUI folder view you are used to.
Navigate to your Project_0 folder using bash.
cd ~/Project_0
Now we are in a suitable location, let’s create a directory called test.
To do this we use the mkdir command as follows (you saw this above in tab auto-completion):
mkdir test
You should see this appear in the GUI view, and if you now enter ls, you should also see this directory in your output.
Importantly, the mkdir command above will only make a directory directly below the one we are currently in as we have used a relative path.
If automating this process via a script it is very important to understand the difference between absolute and relative paths, as discussed above.
Adding Options To Commands
So far, the commands we have used were given either without the use of any subsequent arguments, e.g. pwd and ls, or with a specific directory as the second argument, e.g. cd ../ and ls /.
Many commands have the additional capacity to specify different options as to how they perform, and these options are often specified between the command name, and the file (or path) being operated on.
Options are commonly a single letter prefaced with a single dash (-), or a word prefaced with two dashes (--).
The ls command can be given with the option -l specified between the command and the directory and gives the output in what is known as long listing format.
Inspect the contents of your current directory using the long listing format.
Please make sure you can tell the difference between the characters l (lower-case letter ‘l’) and 1 (number one).
ls -l
The above will give one or more lines of output, and one of the lines should be something similar to:
drwxrwxr-x 2 a1071750 a1071750 4096 Feb 23 09:40 Project_0
where hh:mm is the time of file/directory creation.
The letter d at the beginning of the initial string of codes drwxrwxrwx indicates that this is a directory.
These letters are known as flags which identify key attributes about each file or directory, and beyond the first flag (d) they appear in strict triplets.
The first entry shows the file type and for most common files this entry will be -, whereas for a directory we will commonly see d.
Beyond this first position, the triplet of values rwx simply refer to who is able to read, write or execute the contents of the file or directory.
These three triplets refer to 1) the file’s owner, 2) the group of users that the owner belongs to and 3) all users, and will only contain the values “r” (read), “w” (write), “x” (execute) or “-“ (not enabled).
These are very helpful attributes for data security, protection against malicious software, and accidental file deletions.
The entries a1234567 a1234567 respectively refer to who is the owner of the directory (or file) and to which group of users the owner belongs.
Again, this information won’t be particularly relevant to us today, but this type of information is used to control who can read and write to a file or directory.
Finally, the value 4096 is the size of the directory structure in bytes, whilst the date and time refer to when the directory was created.
Let’s look in your home directory (~).
ls -l ~
This directory should contain numerous folders.
There is a - instead of a d at the beginning of the initial string of flags indicates the difference between any files and directories.
On Ubuntu files and directories will also be displayed with different colours.
Can you see only folders, or do you have any files present in your home directory?
There are many more options that we could specify to give a slightly different output from the ls command.
Two particularly helpful ones are the options -h and -R.
We could have specified the previous command as
ls -l -h ~
The -h option will change the file size to human-readable format, whilst leaving the remainder of the output unchanged.
Try it and you will notice that where we initially saw 4096 bytes, the size is now given as 4.0K, and other file sizes will also be given in Mb etc.
This can be particularly helpful for larger files, as most files in bioinformatics are very large indeed.
An additional option -R tells the ls command to look through each directory recursively.
If we enter
ls -l -R ~
the output will be given in multiple sections.
The first is what we have seen previously, but following that will be the contents of each sub-directory.
It should become immediately clear that the output from setting this option can get very large and long depending on which directory you start from.
It’s probably not a good idea to enter ls -l -R / as this will print out the entire contents of your file system.
In the case of the ls command we can also glob all the above options together in the command
ls -lhR ~
This can often save some time, but it is worth noting that not all programmers write their commands in such a way that this convention can be followed. The built-in shell commands are usually fine with this, but many NGS data processing functions do not accept this convention.
Question
The letter l and the number 1 are often confused in text, but have different meanings. What is the difference in behaviour of ls when run with the -1 (digit) and -l (letter) options? How does ls -1 differ from ls without options?
How To Not Panic
It’s easy for things to go wrong when working in the command-line, but if you’ve accidentally:
- set something running which you need to exit or
- if you can’t see the command prompt, or
- if the terminal is not responsive
there are some simple options for stopping a process and getting you back on track. Some options to try are:
| Command | Result |
|---|---|
| Ctrl+C | Kill the current job |
| Ctrl+D | End of input |
| Ctrl+Z | Suspend current job |
Ctrl+C is usually the first port of call when things go wrong.
However, sometimes Ctrl+C doesn’t work but Ctrl+D or Ctrl+Z will. If you use Ctrl+Z you will need to terminate the process with kill %1.
Manuals and Help Pages
Accessing Manuals
In order to help us find what options are able to be specified, every command available from the shell has a manual, or a help page which can take some time to get familiar with.
These help pages are displayed using the pager known as less which essentially turns the terminal window into a text viewer so we can display text in the terminal window, but with no capacity for us to edit the text, almost like primitive version of Acrobat Reader.
To display the help page for ls enter the command
man ls
As before, the space between the arguments is important and in the first argument we are invoking the command man which then looks for the manual associated with the command ls.
To navigate through the manual page, we need to know a few shortcuts which are part of the less pager.
Although we can navigate through the less pager using up and down arrows on our keyboards, some helpful shortcuts are:
| Key | Action |
|---|---|
| Enter | go down one line |
| Spacebar | go down one page (i.e. a screenful) |
| B | go backwards one page |
| < | go to the beginning of the document |
| > | go to the end of the document |
| Q | quit |
Look through the manual page for the ls command.
Question
If we wanted to hide the group names in the long listing format, which extra options would we need set when searching our home directory?
We can also find out more about the less pager by calling it’s own man page.
Type the command:
man less
and the complete page will appear.
This can look a little overwhelming, so try pressing h which will take you to a summary of the shortcut keys within less.
There are a lot of them, so try out a few to jump through the file.
A good one to experiment with would be to search for patterns within the displayed text by prefacing the pattern with a slash (/).
Try searching for a common word like the or to to see how the function behaves, then try searching for something a bit more useful, like the word move.
Accessing Help Pages
As well as entering the command man before the name of a command you need help with, you can often just enter the name of the command with the options -h or --help specified.
Note the convention of a single hyphen which indicates an individual letter will follow, or a double-hyphen which indicates that a word will follow.
Unfortunately the methods can vary a little from command to command, so if one method doesn’t get you the manual, just try one of the others.
Sometimes it can take a little bit of looking to find something and it’s important to realise we won’t break the computer or accidentally launch a nuclear bomb when we look around. It’s very much like picking up a piece of paper to see what’s under it. If you don’t find something at first, just keep looking and you’ll find it eventually.
Questions
Try accessing the documentation for the command man all the ways you can think of. Was there a difference in the output depending on how we asked to view the documentation? Could you access the documentation for the ls command all three ways?
Some More Useful Tricks and Commands
A series of commands to look up
So far we have explored the commands pwd, cd, ls and man as well as the pager less.
Inspect the man pages for the commands in the following table and fill in the appropriate fields.
Have a look at the useful options and try to understand what they will do if specified when invoking the command.
Write your answers on a piece of paper, or in a plain text file.
| Command | Description of function | Useful options |
|---|---|---|
man |
Display on-line manual | -k |
pwd |
Print working directory, i.e show where you are | none commonly used |
ls |
List contents of a directory | -a, -h, -l |
cd |
Change directory | (scroll down in man builtins to find cd) |
mv |
-b, -f, -u |
|
cp |
-b, -f, -u |
|
rm |
-r (careful…) |
|
mkdir |
-p |
|
cat |
||
less |
||
wc |
-l |
|
head |
-n# (e.g., -n100) |
|
tail |
-n# (e.g., -n100) |
|
echo |
-e |
|
cut |
-d, -f, -s |
|
sort |
||
uniq |
||
wget |
||
gunzip |
Putting It All Together
Now we’ve learned about a large number of commands, let’s try performing something useful. We’ll download a file from the internet, then look through the file. In each step remember to add the filename if it’s not given!
- Use the
cdcommand to make sure you are in the directoryProject_0 - Use the command
wgetto download thegfffileftp://ftp.ensembl.org/pub/release-89/gff3/drosophila_melanogaster/Drosophila_melanogaster.BDGP6.89.gff3.gz - Now unzip this file using the command
gunzip. (Hint: After typinggunzip, use tab auto-complete to add the file name.) - Change the name of the file to
dm6.gffusing the commandmv Drosophila_melanogaster.BDGP6.89.gff3 dm6.gff - Look at the first 10 lines using the
headcommand - Change this to the first 5 lines using
head -n5 - Look at the end of the file using the command
tail - Page through the file using the pager
less - Count how many lines are in the file using the command
wc -l
Regular Expressions
Introduction
Regular expressions are a powerful & flexible way of searching for text strings amongst a large document or file.
Most of us are familiar with searching for a word within a file, but regular expressions allow us to search for these with more flexibility, particularly in the context of genomics.
For example, we could search for a sequence that is either AGT or ACT by using the patterns A[GC]T or A(G|C)T.
These two patterns will search for an A, followed by either a G or C, then followed strictly by a T.
Similarly a match to ANNT can be found by using the patterns A[AGCT][AGCT]T or A[AGCT]{2}T.
We’ll discuss that syntax below, so don’t worry if those patterns didn’t make much sense.
Whilst the bash shell has a great capacity for searching a file to matches to regular expressions, this is where languages like perl and python offer a great degree more power.
The command grep
The built-in command which searches using regular expressions in the terminal is grep, which stands for global regular expression print.
This function searches a file or input on a line-by-line basis, so patterns contained within a line can be found, but patterns split across lines are more difficult to find.
This can be overcome by using regular expressions in a programming language like Python or Perl.
The man grep page (grep --help | less for those without man pages) contains more detail on regular expressions under the REGULAR EXPRESSIONS header (scroll down a few pages).
As can be seen in the man page, the command follows the form grep [OPTIONS] 'pattern' filename
The option -E is preferable as it it stand for Extended, which we can also think of as Easier.
As well as the series of conventional numbers and characters that we are familiar with, we can match to characters with special meaning, as we saw above where enclosing the two letters in brackets gave the option of matching either.
| Special Character | Meaning |
|---|---|
| \w | match any letter or digit, i.e. a word character |
| \s | match any white space character, includes spaces, tabs & end-of-line marks |
| \d | match any digit from 0 to 9 |
| . | matches any single character |
| + | matches one or more of the preceding character (or pattern) |
| * | matches zero or more of the preceding character (or pattern) |
| ? | matches zero or one of the preceding character (or pattern) |
| {x} or {x,y} | matches x or between x and y instances of the preceding character |
| ^ | matches the beginning of a line (when not inside square brackets) |
| $ | matches the end of a line |
| () | contents of the parentheses treated as a single pattern |
| [] | matches only the characters inside the brackets |
| [^] | matches anything other than the characters in the brackets |
| | | either the string before or the string after the “pipe” (use parentheses) |
| \ | don’t treat the following character in the way you normally would. This is why the first three entries in this table started with a backslash, as this gives them their “special” properties. In contrast, placing a backslash before a . symbol will enable it to function as an actual dot/full-stop. |
Pattern Searching
In this section we’ll learn the basics of using the grep command & what forms the output can take.
Firstly, we’ll need to get the file that we’ll search in this section.
First change into your test directory using the cd command, then enter the following, depending on your operating system:
cp ~/data/intro_bash/words words
Now page through the first few lines of the file using less to get an idea about what it contains.
Let’s try a few searches, and to get a feel for the basic syntax of the command, try to describe what you’re searching for on your notes BEFORE you enter the command. Do the results correspond with what you expected to see?
grep -E 'fr..ol' words
grep -E 'fr.[jsm]ol' words
grep -E 'fr.[^jsm]ol' words
grep -E 'fr..ol$' words
grep -E 'fr.+ol$' words
grep -E 'cat|dog' words
grep -E '^w.+(cat|dog)' words
In the above, we were changing the pattern to extract different results from the files.
Now we’ll try a few different options to change the output, whilst leaving the pattern unchanged.
If you’re unsure about some of the options, don’t forget to consult the man page.
grep -E 'louse' words
grep -Ew 'louse' words
grep -Ewn 'louse' words
grep -EwC2 'louse' words
grep -c 'louse' words
In most of the above commands we used the option -E to specify the extended version of grep.
An alternative to this is to use the command egrep, which is the same as grep -E.
Repeat a few of the above commands using egrep instead of grep -E.
Capturing text is something you may want to do, however these operations in bash are beyond the scope of this course.
To perform this we usually use the Stream EDitor sed and this will be covered in part 2 of this practical.
For those who are interested, there is a tutorial available at http://www.grymoire.com/Unix/Sed.html.
A useful pair of websites to test your regular expressions are available at https://regex101.com/ and https://regexr.com/. This can be very handy.